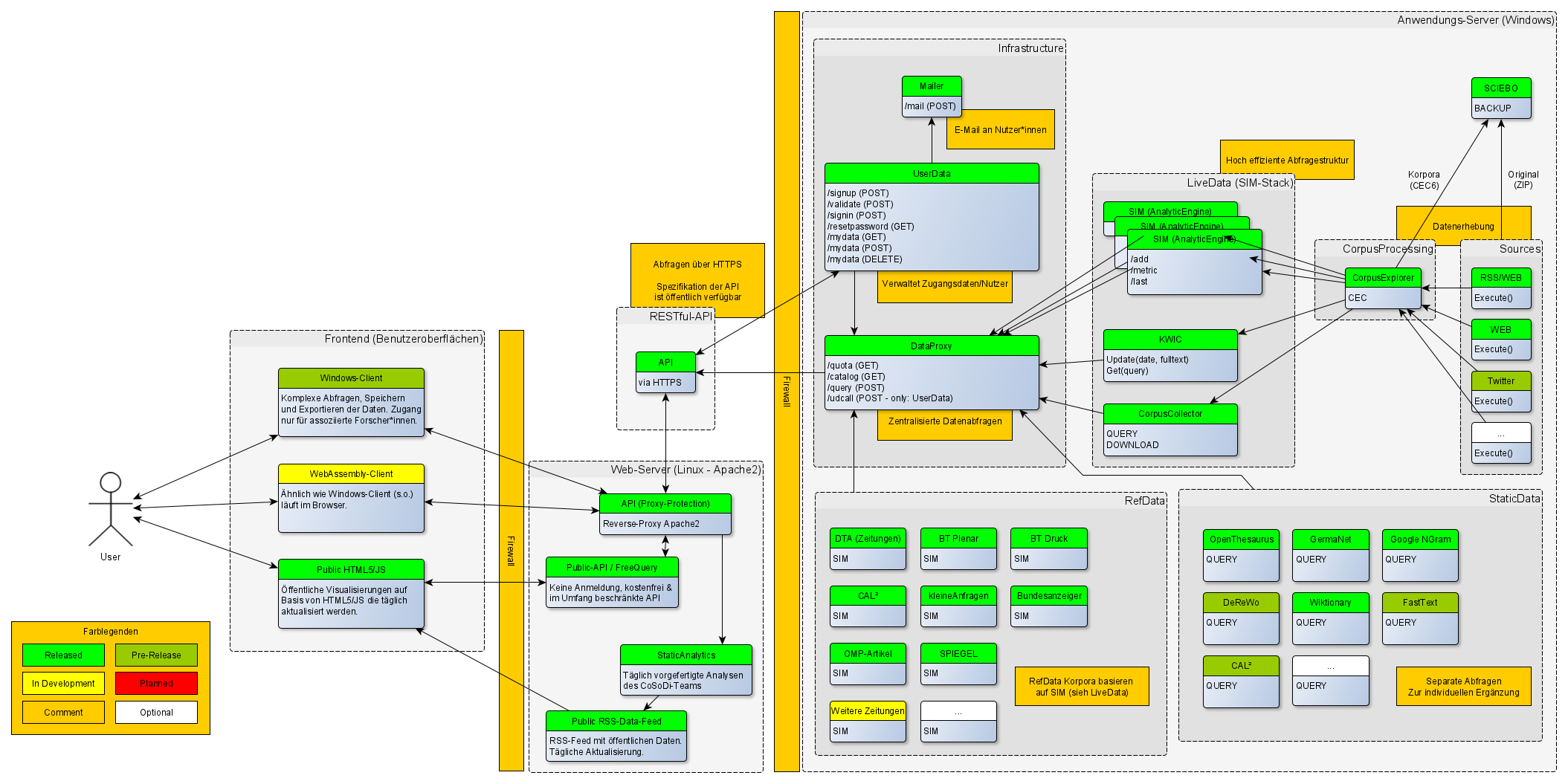
Diese Version ist das erste offizielle Release der DiskursBarometer Micro-Service-Plattform. Bei Knoten/Rechtecken mit einer Überschrift und einer Beschreibung handelt es sich um Programme oder Programmoberflächen. Bei allen serverseitigen Programmen handelt es sich um REST basierte Microservices. Server und besondere Entitäten (z. B. Frontend oder Social Media) sind als Gruppen dargestellt. Datenfluss erfolgt in Pfeilrichtung. Anstelle der Nutzer*in (User) können verschiedene Personengruppen stehen. Diese Personengruppen haben innerhalb der Plattform verschiedene Zugriffsrechte. Die Rechteverwaltung wird durch den Microservice „UserData“ übernommen. Die Kommunikation ist transportverschlüsselt.-Aktuell kommen lediglich ein Windows-Server (6 Kerne, 6 GB RAM) und ein Linux-Server (4 Kerne, 6 GB RAM) zum Einsatz. Das System kann bei Bedarf horizontal und vertikal skaliert werden.
- Frontend (Benutzeroberflächen)
Es sind mehrere Arten von Benutzeroberflächen (kurz GUI) vorgesehen.- Windows-Client:
Der Windows-Client ist die mächtigste GUI. Nutzer*innen installieren diese GUI auf ihrem lokalen Windows Rechner. Mit diesem Frontend kann auf eine Vielzahl von Daten zugegriffen werden. Die Daten können lokal gespeichert und auch exportiert werden. Nur assoziierte Forscher*innen haben Zugriff auf dieses Frontend. Die GUI wird gerade intern getestet. - WebAssembly:
WebAssembly ist ein neuer offener Standard für dynamische Webinhalte. Früher wurde für derartige Inhalte Flash oder Java verwendet – diese Techniken sind veraltet und stehen auf absehbare Zeit nicht mehr zur Verfügung. WebAssembly ist zertifiziert und wird von allen modernen Webbrowsern unterstützt. WebAssembly ist wesentlich schneller bei der Analyse von großen Daten als vergleichbarer Code mit JavaScript. Nur assoziierte Forscher*innen haben Zugriff auf dieses Frontend. Die GUI befindet sich aktuell in einem frühen Entwicklungsstadium. - Public HTML5/JS:
GUI für alle Besucher*innen der Webseite DiskursMonitor.de – Die GUI bietet verschiedene vordefinierte Visualisierungen, die vom WebService „StaticAnalytics“ täglich neu erzeugt werden. Zudem erlaubt die GUI Zugriff auf die Public-API und ermöglicht so einfache Abfragen auch ohne vorherige Registrierung. Diese GUI ist unter https://diskursmonitor.de/barometer erreichbar.
- Windows-Client:
- Web-Server (Linux)
Dies ist der Server auf dem auch die Webseite diskursbarometer.de läuft. Dieser Server stellt folgende Dienste bereit, die Zugriffe auf die Daten ermöglichen.- API (Proxy-Protection) [ehem. „Apache2 / ReverseProxy“):
Grundlage ist die Reverse-Proxy Funktion des Apache2-Servers, mit erweiterten Filter- und Sicherungsfunktionen. Anfragen an die API („RESTful-API“-Spezifikation) werden nach einer Sicherheitsprüfung weitergeleitet. Nur assoziierte Forscher*innen haben Zugriff auf diese API. - Public-API / FreeQuery:
Die Public-API kann ohne vorherige Anmeldung genutzt werden. Die Dokumentation finden Sie hier (OpenAPI 3 YAML). - StaticAnalytics:
Wird vom Server mittels CRON (zeitgesteuerte Aufgabe) gestartet. Prüft nach dem Start, ob sich Daten geändert haben. Falls neue Daten vorliegen, werden die davon abhängigen Analysen neu berechnet. Neuberechnungen werden zudem über den Public RSS-Data-Feed (s. u.) bekannt gemacht. - Public RSS-Data-Feed:
Wird vom Webservice „StaticAnalytics“ erzeugt und verweist auf statisch generierten Daten. Diese können frei genutzt werden. Es handelt sich dabei um aggregierte Daten im JSON-Format. Die Dokumentation finden Sie hier.
- API (Proxy-Protection) [ehem. „Apache2 / ReverseProxy“):
- API
Zentrale API – REST basiert. Zugriff erfordert eine vorherige Registrierung. - Anwendungs-Server (Windows)
Dieser Server ist das Herzstück und führt Sammlung, Aufbereitung und Analysen durch.- Infrastructure
Alle Services sind für den Betrieb essenziell.- Mailer
Versendet Mails (Registrierung / Passwort ändern / Berichte und Analyseergebnisse). - UserData [Weitere Informationen zur REST-API (zentraler Nutzerdienst) (OpenAPI 3.0 YAML)]
Dies ist der zentrale Nutzerdienst. Nutzer können sich hier registrieren, anmelden und ihre personenbezogenen Daten einsehen und ändern (inkl. Passwort).
Der Service teilt bei der Anmeldung eines registrierten Benutzers automatisch einen verfügbaren DataProxy zu (s. u.). - DataProxy [Weitere Informationen zur REST-API (wissenschaftlicher Daten- und Analyse-Proxy) (OpenAPI 3.0 YAML)]
Der DataProxy listet alle verfügbaren Daten (/catalog), gibt Auskunft über die Tages-Quota des Nutzers (/quota) und überwacht diese. Außerdem leitet er Anfragen an Webservices weiter, die mit der Analyse betraut sind (/query).
- Mailer
- LiveData (SIM-Stack)
Die Services für die LIVE-Korpora führen die Analysen durch.- SIM (steht für SingleIndexMetric)
Ein SIM basiert auf der CorpusExplorer Console (cec) – mit ihr werden die Korpora ausgewertet.
Ein SIM ist mit einer einfachen Datei frei konfigurierbar. Für die Konfiguration der aktuell mehreren Dutzend SIMs existiert zudem ein eigenes Konfigurationsprogramm.
Die Konfiguration umfasst (A) welcher Befehl auf der CEC ausgeführt werden soll und (B) wie dieser Befehl von der Datenbank (basierend auf RocksDB – ein Key/Value-Store mit vorgeschaltetem Bloom-Filter) verarbeitet wird – diese Verarbeitungsart wird intern als DatabaseBehavior bezeichnet. Folgende DatabaseBehavior stehen zur Verfügung:- date-value
Die gesamte Ausgabe der CEC wird als Tageswert in die Datenbank eingelesen. Abfragen zu einem Tag geben dann alle Daten zurück. Bsp.: Die Abfrage nach 2020-01-18 ergibt bei einem frequency1-Service alle Frequenzen des Korpus „2020-01-18“. - dictionary
Wird im Zusammenhang mit dem CEC-Befehl ‚corresponding‘ verwendet – erlaubt das Auflösen von Relationen zwischen Layer-Werten. Bsp.: Die reduzierende Abfrage nach „Häuser“ liefert „Haus“, die expandierende Abfrage nach „Haus“ liefert „Häuser“, „HAUS“, „Häusern“ etc. – die bidirektionale (bidirektional -> Reduktion + Expansion) Abfrage zu „Häuser“ liefert „Häuser“, „HAUS“, „Häusern“ etc. - value-date
Führt zunächst wie „date-value“ eine Abfrage zu allen Tageswerten aus. Ordnet dann die Werte zu. So kann z. B. nach „Haus“ gefragt werden und alle datierten Frequenzen werden zurückgegeben. - value-date-fs
Es zeigt sich, das „value-date“ ab einer gewissen Größe (viele Werte/Token * viele Tage) sehr lange für die Erstellung eines Index benötigt. Daher wurde eine Filesystem (FS) basierte Lösung entwickelt, die wesentlich effizienter arbeitet (schnellere Inserts / minimal langsamere Reads / bessere Parallelisierung).
- date-value
- KWIC
Der KWIC-Service steht aktuell nur für die LIVE-Korpora zur Verfügung. Externen Forscher*innen wird aktuell nur Zugriff auf die letzten 30 Tage gewährt. Die KWIC-Suche erlaubt einfache Abfragen. Die Suche ist extrem schnell (Rückgabezeiten unter 250ms) und sehr ressourcenschonend (ca. 800 MB RAM – für ca. 500 Mio. Token). - CorpusCollector
Der CorpusCollector erlaubt im Gegensatz zur KWIC-Suche komplexe Abfragen und individuelle Korpuszusammenstellungen. Der CorpusCollector ist nur für assoziierte Forscher*innen vorgesehen. Er bietet Zugriff auf alle LIVE-Korpora (nicht nur 30 Tage). Die Ergebnisse werden als CEC6-Korpora geliefert. Deren Berechnung und Zusammenstellung erfolgt in Zeiten, in denen der Server nicht oder nur wenig ausgelastet ist.
- SIM (steht für SingleIndexMetric)
- RefData
Die Korpora unter RefData nutzen den SIM-Stack (s. o.), jedoch ohne KWIC und CorpusCollector (da diese Korpoa für Assoziierte verfügbar sind). Folgende Korpora stehen zur Verfügung:- DTA (Zeitungen)
Historisches Zeitungskorpus aus dem Deutschen Text-Archiv
[Quelle] - BT-Plenar
Bundestags Plenarprotokolle
[Quelle] - BT-Druck
Bundestags Drucksachen
[Quelle] - CAL²
Hintergrund ist die CEC6 (CorpusExplorer) Version des CAL²-Korpus
[Quelle] - kleineAnfragen
Kleine und große Anfragen der Landesparlamente und Antworten dazu.
[Quelle] - Bundesanzeiger
[Quelle] - OMP-Artikel
Artikel aus dem OneMillionPosts-Korpus (nur Zeitungsartikel – keine Leserkommentare)
[Quelle] - SPIEGEL
Alle frei verfügbaren Artikel des Spiegel-Magazins.
[nicht frei verfügbar] - Neues Deutschland
Alle Artikel der Zeitung „Neuen Deutschland“. In Vorbereitung.
[nicht frei verfügbar]
- DTA (Zeitungen)
- CorpusProcessing
Alle Rohdaten werden mittels CorpusExplorer aufbereitet. - SCIEBO
Dient aktuell als Backup-Speicher. - Sources
Die aktuelle Quellen:- RSS/WEB & WEB
Initial eine Liste mit Webseiten/RSS-Feeds die Artikel über die DPA, google news posten. Ergänzt durch ausgewählte Webseiten. - Twitter
Aktuell nicht im Einsatz. Könnten aktuelle Tweets erheben. - …
Weitere Quellen möglich
- RSS/WEB & WEB
- StaticData
StaticData umfasst keine Korpora im klassischen Sinn. Vielmehr beinhalten diese Services Zusatzinformationen.- OpenThesaurus
- GermaNet
- Google NGram – aktuell nicht aktiv
- DeReWo – aktuell nicht aktiv
- Wiktionary
- FastText – aktuell nicht aktiv
word2vec für CAL² und für alle Texte aus LIVE in 2019. - CAL²
Portal – Promotionsprojekt von Isabell Gauer. Nicht identisch mit „RefData / CAL²“. Start Q2/Q3 2020. - …
Weitere StaticData möglich.
- Infrastructure