Das DiskursBarometer bietet einen datengestützten, quantifizierenden Einblick in die aktuelle sprachliche und diskursive Großwetterlage. Für dieses automatische Monitoring werden täglich tausende Texte aus öffentlich zugänglichen Online-Portalen erfasst, computerlinguistisch aufbereitet und mithilfe von Text-Mining-Verfahren ausgewertet. Langfristiges Ziel ist, Metriken zu entwickeln und bereitzustellen, die bestimmte Facetten diskursiver Dynamiken in Abhängigkeit von Zeitverlauf, Medien, AutorInnen u.a. hinweg abbilden. Nähere Erläuterungen finden Sie in einem Hintergrund-Dossier.

Diskursbarometer-Metriken
Work in Progress
Die Entwicklung von Diskursmetriken ist in vollem Gange. Die hier gezeigten Metriken haben daher eine rein illustrative Funktion, um Grundgedanke und Ziel des Ansatzes zu veranschaulichen.
Spekulationsindex
Der Spekulationsindex durchsucht unser Textkorpus auf Basis von Adverbien darauf hin, wie häufig sich am gestrigen Tag Autor*innen spekulativ-vermutend über die Welt geäußert haben.
Kontroversitätsindex
Diese Metrik versucht zu erfassen, wie häufig im LIVE-Korpus des Vortags widerstreitende Perspektiven auf die Welt – also semantische Kämpfe – zum Ausdruck kommen.
Ungewissheitsindex
Der Gewissheitsindex gibt den (antizipierten) Grad an Gewissheit bzw. Unsicherheit an, den Autor*innen am Vortag ihren Äußerungen über die Welt zuschreiben.
Eine Hintergrundinformationen zu den jeweiligen Metriken, sowie Detaildaten und Hintergründe zur Visualisierung finden Sie » hier.
Datenbasis: Aktuelle Größe des LIVE-Korpus
Das DiskursBarometer LIVE-Korpus wächst täglich – daher ändern sich auch täglich alle auf dieser Webseite gezeigten Visualisierungen. Das erste Release des DiskursBarometers umfasst verschiedene interaktive Analysemodule (Frequenz, Kookkurrenz, Schlagwörter, KWIC uvm.) zur Auswertung des LIVE-Korpus. Bis Mitte 2020 planen wir die Freigabe einer API (Programmierschnittstelle) für die akademische Nutzung unserer Korpora. Der API-Fortschritt kann im Entwickler-Blog verfolgt werden. Langfristig (bis Ende 2020) wird das DiskursBarometer um weitere Analysemöglichkeiten ergänzt, die sowohl LIVE- als auch Referenzkorpora verwenden. Eine Übersicht zum LIVE-Korpus und den Referenzkorpora finden Sie auf den entsprechenden Unterseiten. Auf den Hintergrundseiten finden Sie zudem weiterführende Informationen zum wissenschaftlichen und technischen Background. Analysen werden auch mit anderen Teilprojekten wie dem DiskursGlossar, der DiskursReview oder der DiskursWerkstatt verbunden.
Diskursmetriken und interaktive Analysemodule
Folgende Analysemodule und vordefinierten Diskursmetriken stellen wir gegenwärtig online zur Verfügung; sie sind Gegenstand aktueller Forschung im Siegern Team für Computergestützte Sozio- und Diskursanalyse.
» Nähere Informationen zum wissenschaftlichen Hintergrund
Diskursmetriken
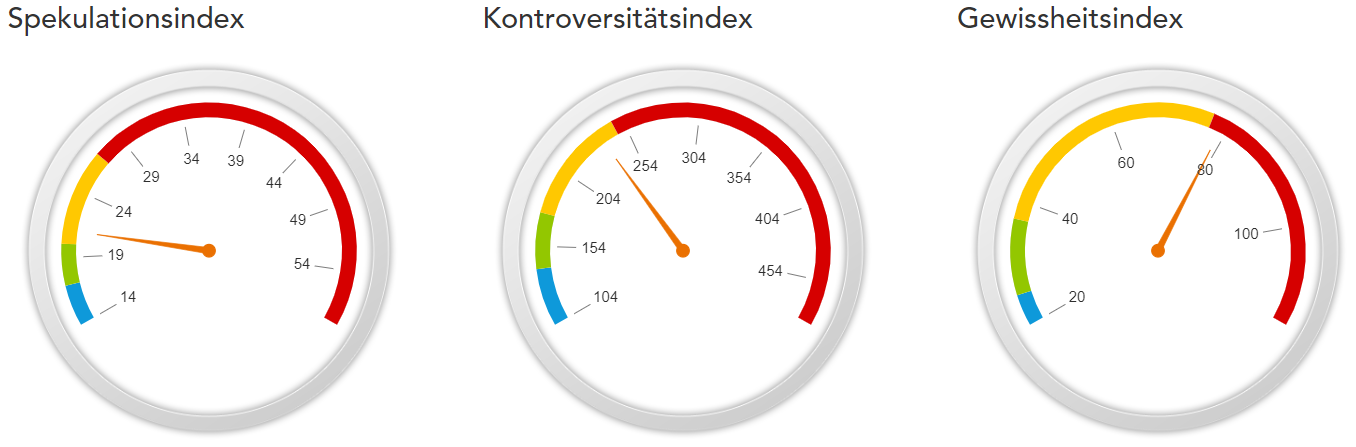
Aktuell laufen die Entwicklungen verschiedener automatisierter Diskursmetriken. Hier finden Sie das Ergebnis der ersten Entwicklung (β1.0)
» Zur Analyse
Frequenzanalyse
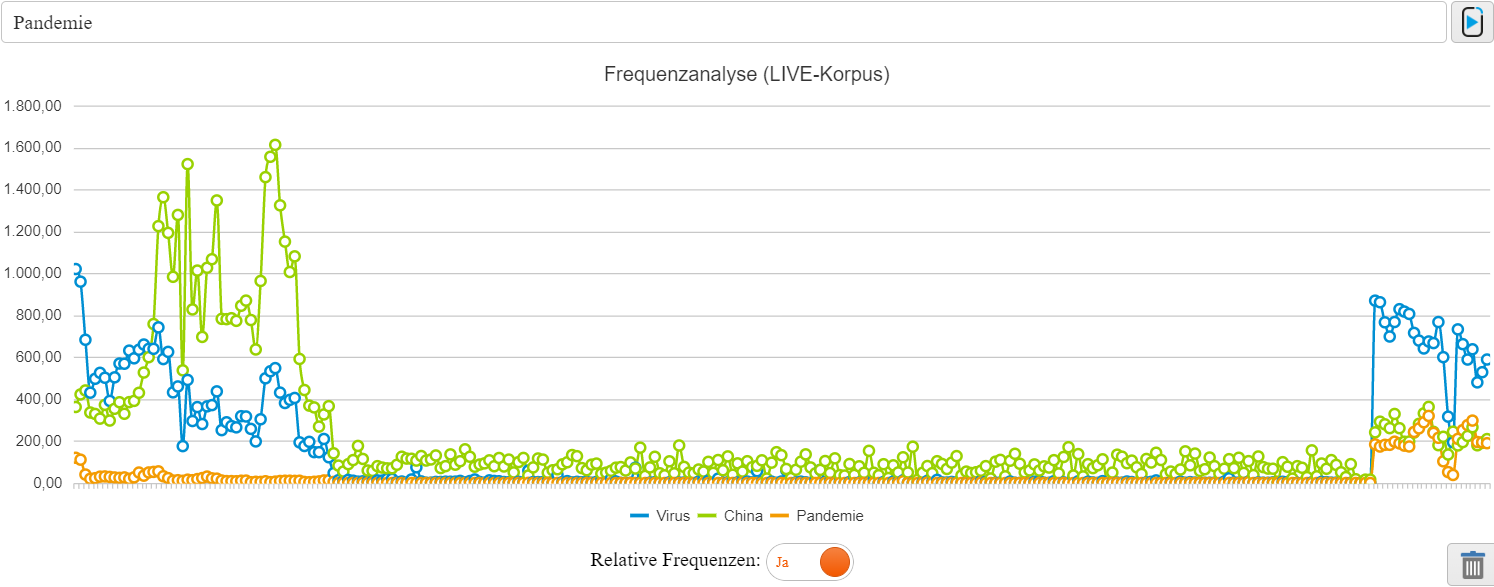
Wir gewähren allen Nutzer*innen die Möglichkeit, in unserem LIVE-Korpus nach einen Wort (Token) zu suchen und deren Tagesfrequenz anzuzeigen.
» Zur Analyse
Schlagwortanalyse

Automatisch ermittelte Schlüsselwörter zeigen an, welche Ausdrücke zu einem Zeitpunkt (verglichen mit einem Referenzzeitpunkt) besonders häufig verwendet werden.
» Zur Analyse
Sentiment
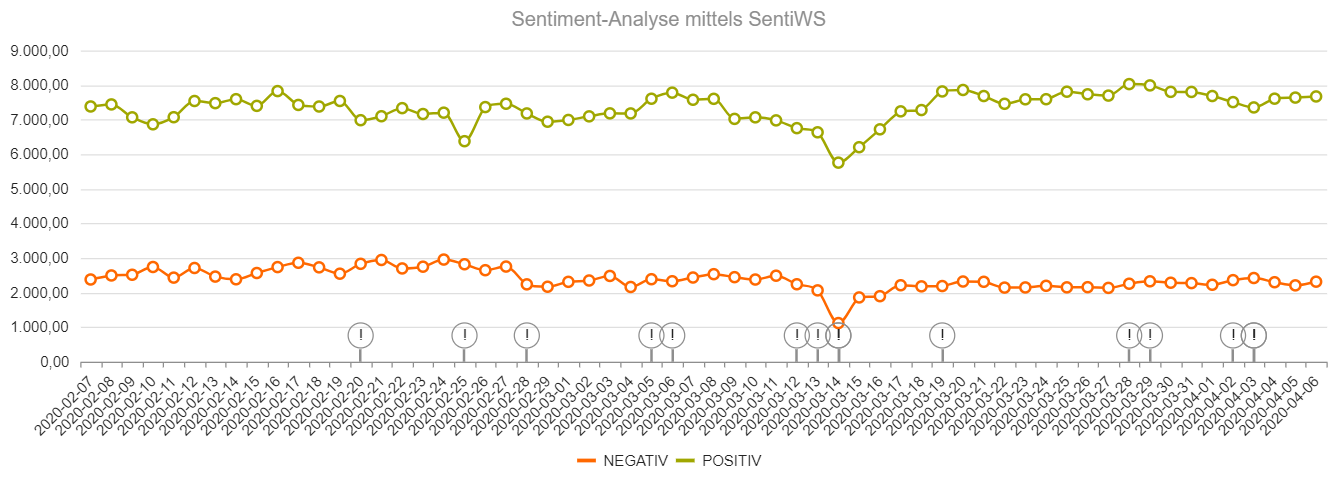
Sentiment-Detection gibt eine grobe Orientierung für die Stimmungsentwicklungen. Die bereitgestellten Analysedaten umfassen einen Zeitraum von 60 Tagen.
» Zur Analyse
N-Gram
Mehrworteinheiten (N-Grams) erlauben die Ermittlung von Sprachgebrauchsmustern. Sie können hier beliebige N-Gramme auf das gesampelte Teilkorpus der letzten drei Tage analysieren.
» Zur Analyse
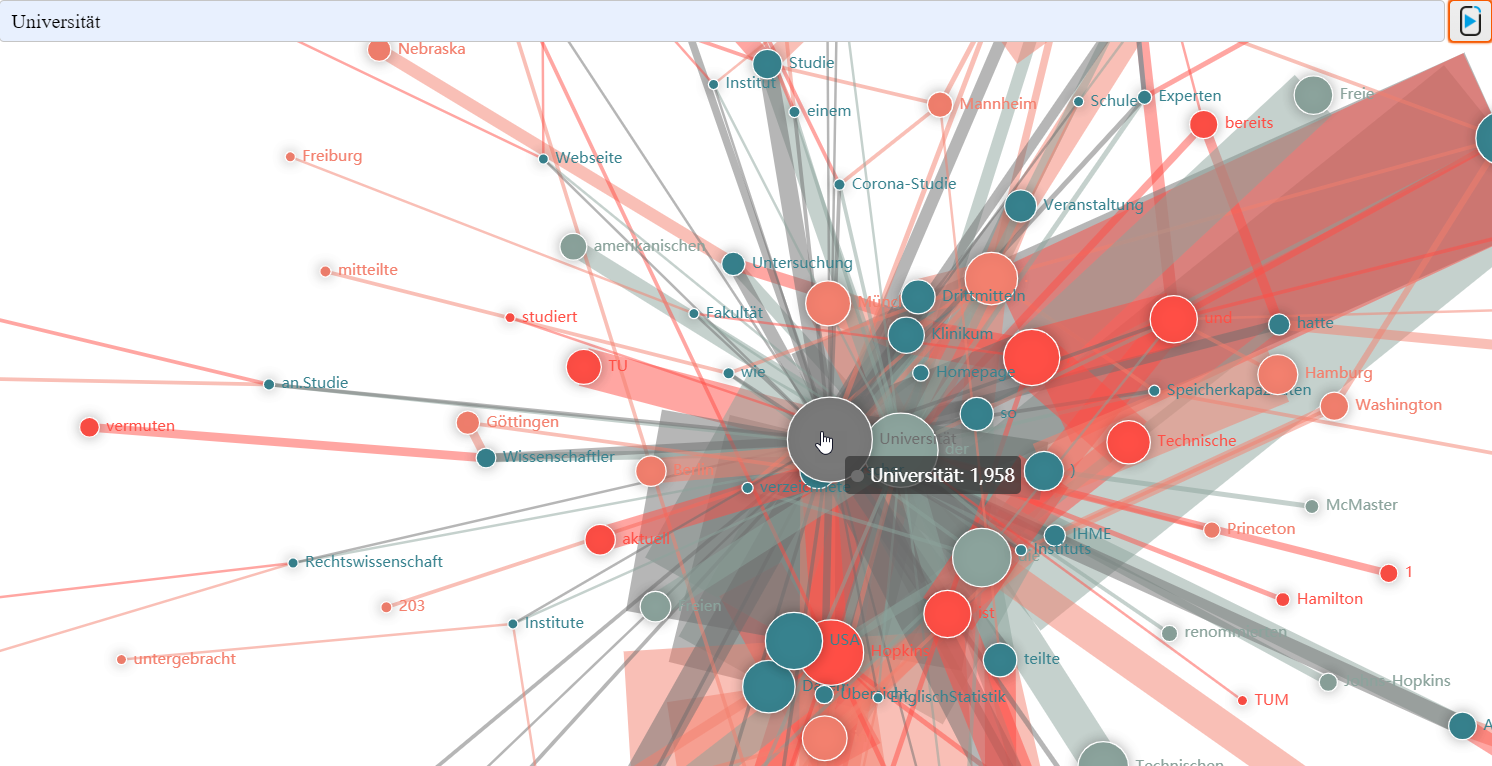
Kookkurrenzen
Kookkurrenzen sind überzufällige Wortpaare innerhalb eines Satzes. Wir bieten eine vergleichende Analyse (zu unterschiedlichen Zeitpunkten) und eine interaktive Analyse des letzten Tages.
» Zur Analyse
Keywords in Kontext

Keywords in Context (KWIC) erlauben die zeilenbasierte Visualisierung eines Suchworts (Keyword). Dies erleichtert den Belegstellenvergleich.
» Zur Analyse
Kritik und Anregungen?
Falls Sie konkrete Verbesserungsvorschläge oder Ideen haben, können Sie uns diese gerne per Kontaktformular mitteilen.