Das DiskursBarometer bietet einen datengestützten, quantifizierenden Einblick in die aktuelle sprachliche und diskursive Großwetterlage. Für dieses automatische Monitoring werden täglich tausende Texte aus öffentlich zugänglichen Online-Portalen erfasst, computerlinguistisch aufbereitet und mithilfe von Text-Mining-Verfahren ausgewertet. Langfristiges Ziel ist, Metriken zu entwickeln und bereitzustellen, die bestimmte Facetten diskursiver Dynamiken in Abhängigkeit von Zeitverlauf, Medien, AutorInnen u.a. hinweg abbilden. Nähere Erläuterungen finden Sie in einem Hintergrund-Dossier.

Diskursbarometer-Metriken für das LIVE-Korpus
Im Rahmen der Forschung des DiskursBaromters werden verschiedene Verfahren und Metriken zur automatisierten Auswertung von Diskursen entwickelt und erprobt (»Hintergrund). Wie ein Barometer für das Wetter, so sollen die Metriken des DiskursBarometers zukünftig eine grobe Orientierung zur allgemeinen Diskursgroßwetterlage bieten. Die nachfolgenden Metriken (aktuell in der Version v1.0 beta) vermitteln einen ersten Eindruck.
Die folgenden Grafiken basieren auf Frequenzanalysen der letzten 30 Tage zu ausgewählten Token und Mehrworteinheiten. In der Tacho-Grafik gibt der Zeiger den aktuellen Wert (gestern) an, die Skala wird anhand der Quartile (letzten 30 Tage) eingefärbt (Blau (Q1), Grün (Q2), Gelb (Q3) und Rot (Q4)) – Eine Erklärung zur Berechnung der Quartile finden Sie hier. Innerhalb der Zeitverläufe werden einige Daten automatisch mit einem Ausrufezeichen („!“) hervorgehobenen. Dabei handelt es sich um im statistischen Sinne auffällig Unregelmäßigkeiten, die das System zu einer manuellen Nachprüfung vorschlägt. Diese Art der Metrisierung steht aktuell noch am Anfang und wird kontinuierlich weiterentwickelt. Wir werden unsere internen Software-Werkzeuge zur Erstellung und Analyse (auch zur Nachprüfung) eigener Diskursmetriken im Laufe des Jahres 2020 interessierten Forscher*innen bereitstellen.
Achtung: Die angegebenen Metrikwerte können nur relativ interpretiert werden: es gibt also nur einen mehr oder weniger spekulativen oder kontroversen Diskurs im Unterschied zu vorhergehenden Tagen. Wir können zum jetzigen Zeitpunkt noch keine Grenzen für einen z.B. „hochspekulativen“ vs. „nicht-spekulativen“ Diskurs benennen.
Work in Progress
Die Entwicklung von Diskursmetriken ist in vollem Gange. Die hier gezeigten Metriken haben daher eine rein illustrative Funktion, um Grundgedanke und Ziel des Ansatzes zu veranschaulichen.
Spekulationsindex
Der Spekulationsindex gibt an, wie häufig sich am gestrigen Tag Autor*innen spekulativ-vermutend über die Welt geäußert haben.
Hier klicken, um mehr zu erfahren
Kontroversitätsindex
Diese Metrik versucht zu erfassen, wie häufig im LIVE-Korpus des Vortags widerstreitende Perspektiven auf die Welt – also im weitesten Sinne semantische Kämpfe – zum Ausdruck kommen.
Hier klicken, um mehr zu erfahren
Ungewissheitsindex
Der Gewissheitsindex gibt an, wie groß das Bedürfnis im Diskurs ist, den Geltungsstatus einer Äußerung über die Welt explizit zu machen.
Hier klicken, um mehr zu erfahren
Wie werden Quartile berechnet?
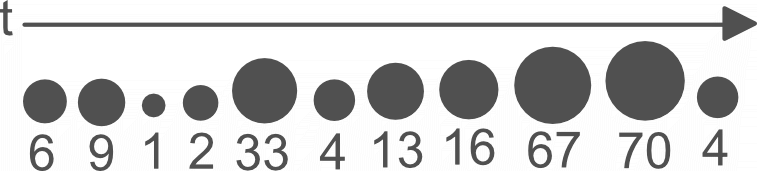
Beispiel 1: Zeitverlauf
Für jede Metrik wird zunächst ein Tageswert ermittelt. Daraus resultieren die unten gezeigten Zeitverläufe. Für die folgenden Ausführungen sei sei der folgende Beispiel-Zeitverlauf gegeben (siehe Beispiel 1).
Da starke Schwankungen auftreten können, ist es sinnvoll, den Median zu bestimmen. Der Median wird in zwei Schritten berechnet. Zuerst werden alle Werte sortiert – die zeitliche Abfolge spielt dabei keine Rolle mehr (siehe Beispiel 2).

Beispiel 2: Sortierte Daten

Beispiel 3: Median
Im zweiten Schritt kann der Median ermittelt werden. Er ist das mittige Element – siehe Beispiel 3. Der Median trennt somit die sortierten Daten in zwei gleichgroße Bereiche (gleiche Anzahl an Werten).
Für die Quartilsberechnung muss der Median für die untere und obere Hälfte berechnet werden (identisches Vorgehen). Dadurch erhält man zwei zusätzliche Mediane. Die insgesamt drei ermittelten Median trennen vier Bereiche voneinander ab (siehe Beispiel 4).
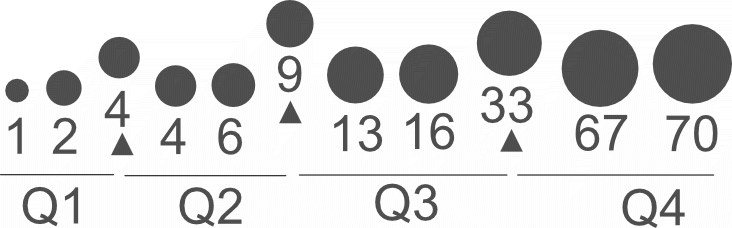
Beispiel 4: Quartile

Beispiel 5: Quartile eingefärbt
Für die Visualisierung werden den Quartilen Farben zugeordnet – siehe Beispiel 5. In diesem Beispiel werden unterhalb der Quartile die Minimal- und Maximalwerte angegeben. Die Farben der Barometer sind übrigens identisch mit den Farben für die Bereichsmarkierungen in den Frequenzverläufen (siehe unten).
Die finale Visualisierung ist ähnlich eines Box-Plots – im Vergleich dazu erfolgt jedoch keine gesonderte Darstellung von Ausreißern. An der Visualisierung lassen sich folgende Dinge ablesen: (1) Minimum/Maximum der gesamten Zeitreihe (30 Tage), sowie (näherungsweise) der Quartile – dies gibt auch Auskunft über die Streuung der Quartile. (2) Der aktuelle Tageswert (gestern) wird als Zeiger dargestellt. Eine Zuordnung zu einem Quartil kann direkt erkannt werden. In Beispiel 6 liegt der Tageswert geringfügig oberhalb des Medians der oberen Hälfte – also im vierten Quartil. Damit ist der Wert (im Vergleich zur Zeitreihe) als sehr hoch einzustufen.

Beispiel 6: Visualisierung
Detaildaten
Die folgenden Grafiken zeigen die Tagesdaten im Zeitverlauf der letzten dreißig Tage. Die farbliche Hinterlegung entspricht den Quartilen (Details zur Berechnung der Quartile finden Sie hier). Mit einem „!“ hervorgehobene Daten wurden durch eine automatische Annomalie-Erkennung als interessant markiert. Diese Daten werden einer manuellen Nachprüfung unterzogen.