
DiskursGlossar
Korpus
Kategorie: Grundbegriffe
Verwandte Ausdrücke: Textkorpus, Teilkorpus, Referenzkorspus, Korpuslinguistik
Siehe auch: Schlagwort, Diskursverschiebung
Autor: Jan Oliver Rüdiger
Version: 1.4 / 31.01.2021
Kurzzusammenfassung
In den Sprach- als auch Literaturwissenschaften versteht man unter Korpora (Plur. Korpora, die / Sing. Korpus, das) ganz allgemein Textsammlungen. Nach Lemnitzer und Zinsmeister (2010, S. 40) ist ein Korpus: „[…] eine Sammlung [authentischer] schriftlicher oder gesprochener Äußerungen in einer oder mehreren Sprachen“. Die Zusammenstellung erfolgt nach verschiedenen wissenschaftlichen Kriterien, die sich am zu untersuchenden Gegenstand orientieren (Bsp. 1: Soll strategische Kommunikation in politischen Reden analysiert werden, so wird ein Korpus aus ‚Politischen Reden‘ zusammengestellt, die strategisch/kommunikative Praktiken enthalten – Bsp. 2: Für die Analyse von Modalpartikeln im Fremdsprachenerwerb wird ein Korpus aus transkribierten Redebeiträgen verschiedener Erwerbsstufen benötigt). Prinzipiell kann ein Korpus auch analog (gedruckt) vorliegen und manuell ausgewertet werden – In der empirischen Linguistik ist ein Korpus aber i. d. R. immer ein digitales (maschinenlesbares) Korpus, das automatisiert (mittels Software) ausgewertet wird.
Erweiterte Begriffsklärung
Korpora bestehen nicht nur aus den Texten (den so genannten Primärdaten), sie umfassen auch eine ganze Reihe weiterer Sekundärdaten. Im Wesentlichen handelt es sich dabei um Metadaten und Annotationen (vgl. hierzu Perkuhn et al. (2012)). Metadaten sind Zusatzinformationen zu einzelnen Texten (z. B. der Titel, Autor*in, Datum, Textsorte etc.). Diese Metadaten können in der Korpusanalyse genutzt werden, um etwa Akteursgruppen, Zeitfenster oder Textsorten miteinander zu vergleichen bzw. sie zueinander in Beziehung zu setzen (z.B. Vergleich von Sprachgebrauchsmuster bestimmter Autor*innen / Unterschiedlicher Sprachgebrauch in zwei oder mehr definierten Zeitfenstern).
Annotationen sind Sekundärdaten, die direkt mit dem Text verknüpft sind. Annotationen können sowohl manuell erstellt oder automatisch erzeugt werden. Elektronische Korpora werden i. d. R. mehrstufig automatisch annotiert. Zusätzliche manuelle Annotationen oder Nachkorrekturen der automatischen Annotation sind je nach Forschungsinteresse notwendig. Folgende automatische Prozessschritte sind weit verbreitet: Zerteilung der Texte in einzelne Sätze, Zerteilung der Sätze in einzelne Token (Unter den Begriff ‚Token‘ fallen sowohl Wortformen (Berg, Berge, Berges etc.) als auch Satzzeichen), automatische Lemmatisierung der Token (Token: Häuser > Lemma: Haus), automatische Zuordnung der Wortart (Token: Berge > Wortart: Nomen), Annotation von Phrasen (Token: Das wundersame Fest > Phrase: Nominalphrase). Ein so aufbereitetes Korpus erlaubt sehr komplexe Analyse- und Abfragemöglichkeiten (z. B.: Suche alle Sätze mit Nominalphrasen, die das Lemma ‚Krise‘ enthalten).
Wie Mukherjee (2009) anmerkt, arbeitet die Sprachwissenschaft bereits in der ‚Vor-Computer-Zeit‘ mit Textsammlungen, also Korpora. So wird u. a. das Beispiel der Konkordanz-Analyse der King James Bibel von Alexander Curden aus dem Jahre 1736 als eine händische Korpusanalyse angeführt. Bei dieser Analyse werden Konkordanzen/Belegsätze geordnet und ggf. gefiltert. Durch diese Art der Darstellung lässt sich der Kontext einfacher erkennen und auswerten. Während man in der ‚Vor-Computer-Zeit‘ auf händische Arbeit angewiesen war (Belege abschreiben/abtippen, ausschneiden, auf Karteikarten aufkleben etc.), kann eine solche Konkordanz-Analyse heutzutage mittels entsprechender Software in Sekundenschnelle auf riesige Korpora angewendet werden. Folgendes Beispiel zeigt eine Konkordanz-Analyse zum Stichwort ‚Europa‘ in Plenarprotokollen des Europäischen Parlaments:
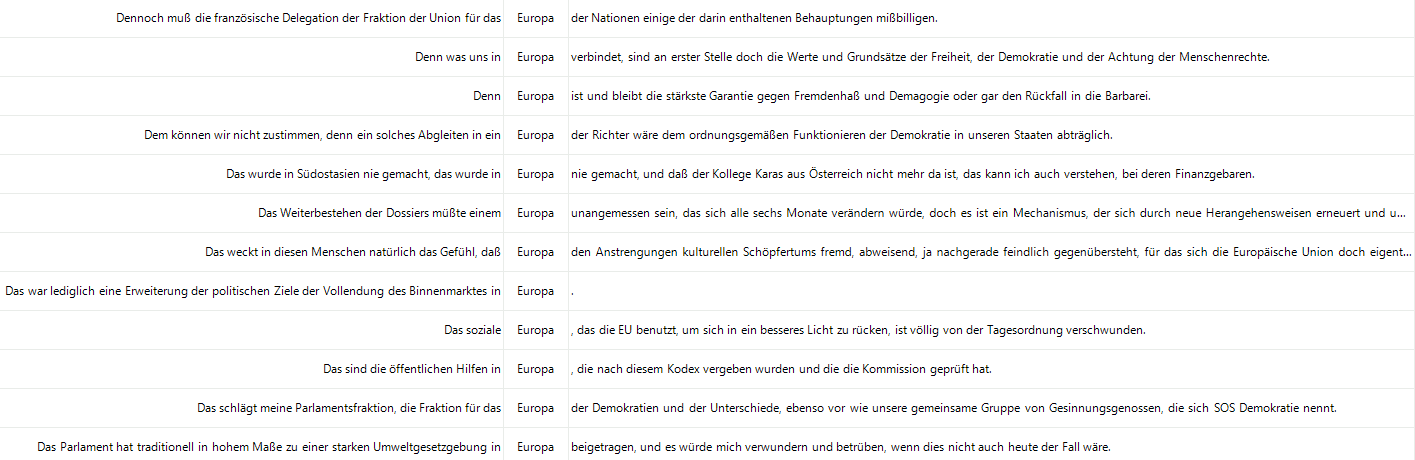
Grafik 1: Konkordanzen als KWIC (Keyword in Context) dargestellt.
Die ersten computergestützten Korpora entstanden Mitte des 20. Jahrhunderts. Das Brown University Corpus of Present-Day American English (vgl. Francis und Kučera (1964) war das erste rein computergestützte Korpus und umfasste bereits eine Million Wörter. Es setzte sich, wie der Name schon andeutet, aus unterschiedlichsten schriftsprachlichen Genres der amerikanischen Gegenwartssprache zusammen. Ebenfalls 1964 entstand mit dem Mannheimer Korpus I (MK_I) am Leibniz-Institut für Deutsche Sprache unter der Leitung von Paul Grebe und Ulrich Engel ein vergleichbares Korpus des Deutschen mit sogar bereits 2,2 Mio. Token. Durch die Verbreitung und schnell steigenden Computerkapazitäten wuchsen auch die Möglichkeiten der Korpuslinguistik. Bereits in den 1990ern erreichte das British National Corpus (BNC) einen Umfang von über 100 Millionen Token. Im Jahr 2000 überschritt das Deutsche Referenz Korpus (DeReKo) – basierend auf dem Projekt Mannheimer Korpus (siehe oben) – die Schwelle von einer Milliarde Token. Mit Stand 02.02.2021 umfasst DeReKo 50 Milliarden Token (vgl. zur Entwicklung auch Kupietz et al. (2018)). Viele, auch kleinere, spezifischere Korpusprojekte entstanden in den letzten Jahrzehnten. Eine gute Ausgangsbasis für eigene Recherchen bietet die Plattform CLARIN – hier sind viele freie Korpus-Ressourcen gelistet.
Für das Teilprojekt Barometer im DiskursMonitor wurden verschiedene freie Korpora als Referenzkorpora aggregiert (eine Beschreibung finden Sie hier). Außerdem wurde eine Infrastruktur entwickelt, die eine LIVE-Analyse ermöglicht. Die Korpora stehen intern für Lehrstuhlprojekte aber auch externen Forschenden zur Verfügung. Besucher*innen der Webseite können auf aggregierte Korpusdaten einfache Analysen durchführen (zu den Analysen).
Beispiele
Korpora dienen nicht nur zur Suche nach Belegen. Auf ein Korpus lassen sich verschiedene (statistische) Analysen anwenden (sowohl auf die primären Textdaten als auch auf die sekundären Metadaten/Annotation – und auch in Kombination [Text <> Metadaten/Annotation]). Einen guten Überblick und eine Einbettung/Anknüpfung in die linguistischen Grundlagen bietet Bubenhofer (2009). Im folgenden haben wir eine Liste mit beispielhaften Analysen zusammengestellt, die auf den Barometer-Korpora (siehe oben) basieren und die Sie selbst explorativ testen können:
- Frequenzanalysen stellen eine einfache und effektive Möglichkeit dar, große Textsammlungen (Korpora) zu untersuchen. Mit der Frequenzanalyse lassen sich verschiedene Fragen beantworten (für detaillierter Informationen siehe Frequenzanalyse):
→ Was sind die häufigsten Token (z. B. Lemmata) in einem Korpus?
→ Wie oft kommt ein bestimmtes Token im Korpus vor?
→ Wie oft kommt ein bestimmtes Token zu einem bestimmten Zeitpunkt vor?
Dadurch wird die oben angesprochene Kombination aus Text und Metadaten (Zeit) zum Analysegegenstand. Das Resultat sind z. B. Zeitverlaufsanalysen. - Eine mögliche Anwendung der oben genannten Frequenzanalyse ist die Sentiment-Analysen (Sentiment von engl. Gefühl/Empfindung). Im Wesentlichen handelt es sich um eine Positiv/Negativ-Frequenzanalyse. Dieses Verfahren hat methodische Grenzen und ist daher nur unter Vorbehalt einsetzbar: Zum einen fixiert das Verfahren die Textoberfläche und erkennt Tiefenstrukturen, Kontexte, Ironie und ähnliche sprachliche Phänomene nicht; zum anderen ist die Erstellung der Ausgangslisten und damit Bewertung von Einzeläußerungen oftmals von der subjektiven Einordnung des/der Bearbeiter*in abhängig. Für weiterführende Informationen zur Sentiment-Analyse siehe hier.
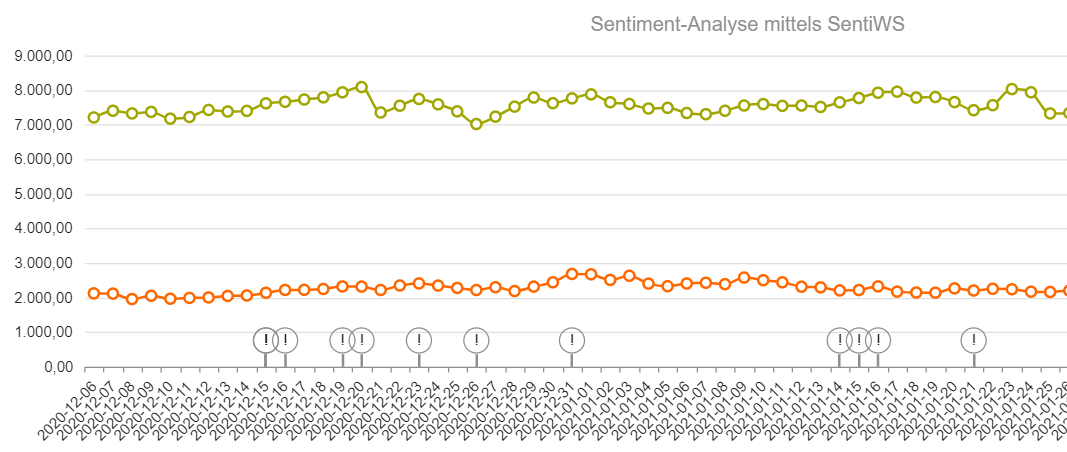
Grafik 3: Sentiment-Detection im diskursmonitor LIVE-Korpus
- Schlagwörter (Keywords) geben Auskunft darüber, welche Ausdrücke zu einem Zeitpunkt (verglichen mit einem anderen Zeitpunkt) besonders auffällig häufig sind. Schlagwörter werden mithilfe eines statistischen Signifikanztests ermittelt (hier: Poisson-Verteilung). Die folgende Auswertung vergleicht unterschiedlich große Zeitabschnitte miteinander und ermöglicht damit, kurzfristige von langfristigen Diskurstrends zu differenzieren. Eine tagesaktuelle Auswertung finden Sie hier.

Grafik 4: Beispiel-Schlagworte
- Kookkurrenz-Analysen – Kookkurrenzen (engl. co-occurrence – gemeinsames Vorkommen) sind zwei Token (hier: Wörter), die innerhalb einer Textmenge besonders häufig zusammen (hier: innerhalb eines Satzes) und selten in anderen Kombinationen vorkommen (z. B. mit anderen Token). Eine interaktive Analyse finden Sie hier.

Grafik 5: Beispiel-Kookkurrenzen
- N-Gramme sind hochfrequente Wortfolgen und gehören zur Analysekategorie der Mehrworteinheiten. Das N steht dabei für eine natürliche Zahl größer 0. Durch N-Gramme lassen sich Mehrwort-Verbindungen und Sprachgebrauchsmuster in Texten identifizieren. Solche Muster können z. B. Floskeln (z. B. „Guten Tag“, „Meine Damen und Herren“ etc.), Phrasen (z. B. „den Tag nicht vor dem Abend loben“ etc.) oder syntaktische Abfolgen realisieren (z. B. „ich gehe ins“ etc.). Weitere Details zu N-Grammen finden Sie hier.

Grafik 6: N-Gramme zu ‚Merkel‘
- Konkordanz-Analyse / KWIC-Analyse
Wie im ersten Nutzungsbeispiel (siehe oben – Konkordanzen) beschrieben, kann eine Konkordanz-Analyse Einblicke in die Realisationsformen eines Token geben. Wenn Sie das einmal selbst ausprobieren möchten, finden Sie hier die Möglichkeit und weiterführende Informationen.

Grafik 7: KWIC-Belege zu Merkel
Literatur
Zitierte Literatur und Belege
-
Bubenhofer, Noah (2009): Sprachgebrauchsmuster. Korpuslinguistik als Methode der Diskurs- und Kulturanalyse. Zugl.: Zürich, Univ., Diss., 2008. Berlin: de Gruyter.
Calzolari, Nicoletta et al. (Hrsg.) (2018): Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018). Miyazaki, Japan: European Language Resources Association (ELRA). -
Francis, W. Nelson; Kučera, Henry (1964): Manual of Information to Accompany‚ A Standard Sample of Present-Day Edited American English, for Use with Digital Computers*. Brown University, Providence. Department of Linguistics.
-
Kupietz, Marc et al. (2018): The German Reference Corpus DeReKo: New Developments – New Opportunities. In: Calzolari, Nicoletta et al. (Hrsg.): Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018). Miyazaki, Japan: European Language Resources Association (ELRA).
-
Lemnitzer, Lothar; Zinsmeister, Heike (2010): Korpuslinguistik. Eine Einführung. Tübingen: Narr Verlag.
-
Mukherjee, Joybrato (2009): Anglistische Korpuslinguistik. Eine Einführung. Berlin: Schmidt.
-
Perkuhn, Rainer; Keibel, Holger; Kupietz, Marc (2012): Korpuslinguistik. Paderborn: Fink.
-
Scherer, Carmen (2014): Korpuslinguistik. Heidelberg: Winter.
-
Stede, Manfred (2007): Korpusgestützte Textanalyse. Grundzüge der Ebenen-orientierten Textlinguistik. Tübingen: Narr.
Abbildungsverzeichnis
- Abb. 1: Konkordanzen zum Stichwort „Europa“ in den Plenarprotokollen des Europäischen Parlaments als KWIC (Keywords in Context).
- Abb. 2: Screenshot des Beispiels ‚Frequenzverlauf zu ‚SARS-CoV-2‘ auf der Seite des Korpus Onlineartikels. Online unter: https://diskursmonitor.de/glossar/korpus/ ; Zugriff: 20.01.2021.
- Abb. 3: Screenshot der Sentiment-Detection im diskursmonitor LIVE-Korpus. Online unter: https://diskursmonitor.de/barometer/analysen/sentiment-detection/ ; Zugriff: 20.01.2021.
- Abb. 4: Screenshot der Schlagwort-Auswertung. Online unter: https://diskursmonitor.de/barometer/analysen/schlagworte/ ; Zugriff: 20.01.2021.
- Abb. 5: Screenshot der Kookkurrenzen-Auswertung im Live Korpus. Online unter: https://diskursmonitor.de/barometer/analysen/kookkurrenzen/ ; Zugriff: 20.01.2021.
- Abb. 6: Screenshot des N-Gramms im Live Korpus. Online unter: https://diskursmonitor.de/barometer/analysen/ngram/ ; Zugriff: 20.01.2021.
- Abb. 7: Screenshot der KWIC-Belege zu Merkel im Live Korpus. Online unter: https://diskursmonitor.de/barometer/analysen/kwic/ ; Zugriff: 20.01.2021.
Zitiervorschlag
Rüdiger, Jan Oliver (2021): Korpus. In: Diskursmonitor. Glossar zur strategischen Kommunikation in öffentlichen Diskursen. Hg. von der Forschungsgruppe Diskursmonitor und Diskursintervention. Veröffentlicht am 19.04.2021. Online unter: https://diskursmonitor.de/glossar/korpus/.
Grundbegriffe
Begriffsgeschichte
Die Begriffsgeschichte lässt sich allgemein als eine historische Methode beschreiben, die den zeitlichen Wandel der Bedeutungen von bestimmten Ausdrücken untersucht. Da einzelne Worte nie isoliert begegnen und ihre jeweiligen Bedeutungen erst im Kontext größerer sprachlicher Zusammenhänge oder semantischer Felder greifbar werden, verbindet sie sich flexibel mit anderen Methoden historischer Semantik, wie etwa der Diskursgeschichte, der Argumentationsgeschichte oder der Metaphernforschung (Metaphorologie).
Diskurssemantische Verschiebung
Mit dem Begriff der diskurssemantischen Verschiebung wird in der Diskursforschung ein Wandel in der öffentlichen Sprache und Kommunikation verstanden, der auf mittel- oder län-gerfristige Veränderung des Denkens, Handelns und/oder Fühlens größerer Gesellschafts-gruppen hinweist.
Domäne
Der Begriff der Domäne ist aus der soziologisch orientierten Sprachforschung in die Diskursforschung übernommen worden. Hier wird der Begriff dafür verwendet, um Muster im Sprachgebrauch und kollektiven Denken von sozialen Gruppen nach situationsübergreifenden Tätigkeitsbereichen zu sortieren.
Positionieren
Positionieren ist Grundbestandteil menschlicher Kommunikation. Wann immer wir miteinander interagieren und kommunizieren, bringen wir uns selbst, andere und die Objekte, über die wir sprechen, in bestimmte Relationen zueinander.
Deutungsmuster
Unter einem Deutungsmuster wird die problem- und lösungsbezogene Interpretation gesellschaftlicher und politischer Tatbestände verstanden, die Aussicht auf Akzeptanz in sozialen Gruppen hat. Der Begriff des Deutungsmusters hat Ähnlichkeit mit den Begriffen der Theorie und Ideologie. Meist werden gesellschaftlich verbreitete Leitdeutungen, die oft mit Schlagwörtern und Argumentationsmustern einhergehen (wie Globalisierung, Kapitalismus, Leistungsgesellschaft, Chancengleichheit etc.) als Beispiele für Deutungsmuster genannt.
Sinnformel
‚Wer sind wir? Woher kommen, wo stehen und wohin gehen wir? Wozu leben wir?‘ Auf diese und ähnliche existentielle Fragen geben Sinnformeln kondensierte Antworten, die in privaten wie sozialen Situationen Halt und Argumenten in politischen und medialen Debatten einen sicheren Unterbau geben können.
Praktik
Eine Praktik ist ein spezifisches, situativ vollzogenes und sinnhaftes Bündel von körperlichen Verhaltensweisen, an dem mehrere Menschen und Dinge beteiligt sein können (z. B. Seufzen, um Frust auszudrücken, oder einen Beschwerdebrief schreiben, Fußballspielen).
Kontextualisieren
Kontextualisieren wird im allgemeineren bildungssprachlichen Begriffsgebrauch verwendet, um das Einordnen von etwas oder jemandem in einen bestimmten Zusammenhang zu bezeichnen.
Narrativ
Mit der diskursanalytischen Kategorie des Narrativs werden Vorstellungen von komplexen Denk- und Handlungsstrukturen erfasst. Narrative in diesem Sinne gehören wie Schlagwörter, Metaphern und Topoi zu den Grundkategorien der Analyse von Diskursen.
Argumentation
Argumentation bezeichnet jene sprachliche Tätigkeit, in der man sich mithilfe von Gründen darum bemüht, die Richtigkeit einer Antwort auf eine bestimmte Frage zu erweisen. Das kann in ganz verschiedenen Situationen und Bereichen nötig sein, namentlich um eine poli-tische, wissenschaftliche, rechtliche, unternehmerische oder private Angelegenheit zu klären.
Techniken
AI-Washing/KI-Washing
Unter AI-Washing ist die Praxis von Unternehmen oder Organisationen zu verstehen, Produkte, Dienstleistungen oder Geschäftsmodelle mit dem Etikett „Künstliche Intelligenz“ (KI bzw. „Artificial Intelligence“ (AI)) zu versehen, obwohl deren tatsächlicher Einsatz von KI-Technologien entweder stark übertrieben, nur marginal vorhanden oder überhaupt nicht gegeben ist.
Dogwhistle
Unter Dogwhistle wird in Teilen der Forschung eine doppeldeutige Äußerung verstanden, die eine offene und eine verdeckte Botschaft an jeweils eine Zuhörerschaft kommuniziert.
Demonstrieren
« Zurück zur ArtikelübersichtDemonstrieren Kategorie: TechnikenVerwandte Ausdrücke: Auf die Straße gehen, Straßenprotest, Kundgebung, öffentliche Versammlung, Mahnwache, Menschenkette, Marsch, SitzblockadenSiehe auch: Protest, Politische Aktion, Politische Bildung,...
Boykottaufruf
Der Boykottaufruf ist eine Maßnahme, die darauf abzielt, ein Ziel, also meist eine Verhaltensänderung des Boykottierten, hervorzurufen, indem zu einem Abbruch etwa der wirtschaftlichen oder sozialen Beziehungen zu diesem aufgefordert wird.
Tabuisieren
Das Wort Tabuisierung bezeichnet die Praxis, etwas Unerwünschtes, Anstößiges oder Peinliches unsichtbar zu machen oder als nicht akzeptabel zu markieren. Das Tabuisierte gilt dann moralisch als unsagbar, unzeigbar oder unmachbar.
Aus dem Zusammenhang reißen
Das Aus-dem-Zusammenhang-Reißen gehört in den Funktionskreis der Redewiedergabe bzw. der Wiedergabe kommunikativer Ereignisse. Es kann (1) als intentionale argumentativ-polemische Strategie für ganz unterschiedliche diskursive Zielsetzungen von Akteuren genutzt werden, oder (2) es kann SprecherInnen und SchreiberInnen in unbeabsichtigter, fehlerhafter Weise unterlaufen.
Lobbying
Lobbying ist eine Form strategischer Kommunikation, die sich primär an Akteure in der Politik richtet. Beim Lobbying wird ein Bündel von kommunikativen Tätigkeiten mit dem Ziel eingesetzt, die Entscheidungen von Personen mit politischem Mandat oder den Entstehungsprozess von neuen Gesetzestexten interessengeleitet zu beeinflussen.
Karten
Karten dienen dazu, Raumausschnitte im Hinblick auf ausgewählte Charakteristika so darzustellen, dass die Informationen unmittelbar in ihrem Zusammenhang erfasst und gut kommuniziert werden können. Dazu ist es notwendig, Daten und Darstellungsweisen auszuwählen und komplexe und oft umkämpfte Prozesse der Wirklichkeit in einfachen Darstellungen zu fixieren.
Pressemitteilung
Pressemitteilungen sind standardisierte Mitteilungen von Organisationen, die sich an Journalist:innen und andere Multiplikator:innen richten. Sie dienen der offiziellen und zitierfähigen Informationsweitergabe und übernehmen zugleich strategische Funktionen in der öffentlichen Kommunikation und Meinungssteuerung.
Shitstorm
Der Begriff Shitstorm beschreibt eine relativ junge Diskurskonstellation, die seit den 2010er Jahren an Bedeutung gewonnen hat und gemeinhin als Online-Wutausbruch bezeichnet wer-den kann.
Schlagwörter
Brückentechnologie
Ganz allgemein wird unter dem Schlagwort der Brückentechnologie sowohl in den öffentlichen Medien als auch in technisch und wirtschaftlich dominierten Kontexten eine Technologie verstanden, die zeitlich befristet eingesetzt werden soll, bevor in Zukunft der Übergang zu einer als sinnvoller eingeschätzten anderen Technologie möglich ist.
Deindustrialisierung
Der Ausdruck Deindustrialisierung (auch De-Industrialisierung oder als Verb deindustrialisieren) beschreibt im öffentlichen Sprachgebrauch eine negativ bewertete Form des Strukturwandels durch Rückgang von produzierendem Gewerbe.
Nachhaltigkeit
Nachhaltigkeit als ein Schlagwort des öffentlichen Diskurses bezieht sich ganz allgemein auf einen ressourcenschonenderen Umgang mit dem, was uns Menschen der Planet Erde bietet, mit dem Ziel, dass auch nachfolgende Generationen noch die Möglichkeit haben, ähnlich gut zu leben wie wir heute (Generationengerechtigkeit).
Echokammer
Der Begriff der Echokammer steht in seiner heutigen Verwendung vor allem im Zusammenhang mit der Nutzung Sozialer Medien. Er verweist metaphorisch auf einen digitalen Kommunikations- und Resonanzraum, in dem Mediennutzer*innen lediglich Inhalten begegnen, die ihre eigenen, bereits bestehenden Ansichten bestätigen, während abweichende Perspektiven und Meinungen ausgeblendet bzw. abgelehnt werden.
Relativieren
Der Ausdruck relativieren besitzt zwei zentrale Bedeutungsvarianten: In bildungssprachlichen und wissenschaftlichen Kontexten bezeichnet er eine analytische Praxis, bei der Aussagen, Begriffe oder Phänomene durch Bezugnahme auf andere Sachverhalte eingeordnet, differen-ziert und in ihrer Geltung präzisiert werden.
Massendemokratie
Geprägt wurde der Begriff Massendemokratie im ersten Drittel des 20. Jahrhunderts von völkisch-konservativen Akteuren (prominent darunter Carl Schmitt 1926). Der Ausdruck Masse hatte damals bei den bürgerlichen Eliten eine rundum bedrohliche Assoziation.
Social Bots
Als Social Bots werden Computerprogramme bezeichnet, die in der Lage sind, in sozialen Medien Kommunikation menschlicher Nutzer*innen (teilweise) automatisiert nachzuahmen.
Kriegsmüdigkeit
Der Ausdruck Kriegsmüdigkeit bezeichnet die emotionale und physische Erschöpfung von Menschen, die einen Krieg erleben, sowie die gesellschaftliche und politische Ermüdung angesichts langanhaltender Konflikte. Er beschreibt den sinkenden Kampfeswillen bei Kriegsparteien und heute wird er auch für das wachsende Desinteresse an Kriegsthemen in Medien und Öffentlichkeit genutzt.
Woke
Der Ausdruck woke stammt aus dem afroamerikanischen Englisch und bezeichnete dort zunächst den Bewusstseinszustand der Aufgeklärtheit über die Verbreitung von rassistischen Vorurteilen und Diskriminierung unter Angehörigen ethnischer Minderheiten.
Identität
Unter Identität versteht man allgemein die Summe von Merkmalen, die Individuen oder sozialen Kollektiven – etwa Nationen, Organisationen oder sozialen Gruppen – als charakteristisch oder gar als angeboren zugeordnet werden.
Verschiebungen
Dehumanisierung
Mit Dehumanisierung bzw. Anthropomorphisierung werden solche kommunikativen Techniken und Praktiken bezeichnet, die Personen, Sachverhalten oder Gegenständen menschliche Eigenschaften ab- bzw. zusprechen. Dehumanisierung und Anthropomorphisierung können sowohl durch sprachliche Mittel als auch durch andere, z. B. bildliche, Zeichen vollzogen werden.
Kriminalisierung
Kriminalität meint ein Verhalten, das gegen ein Gesetz verstößt. Folglich bedeutet Kriminalisierung im engeren Sinne den Vorgang, durch den Verhalten ungesetzlich gemacht wird – indem Gesetze geschaffen werden.
Versicherheitlichung
In akademischen Kontexten wird Versicherheitlichung in Abgrenzung zu einem naiv-realistischen Sicherheitsverständnis verwendet. Dieses betrachtet Sicherheit als einen universell erstrebenswerten und objektiv feststellbaren Zustand, dessen Abwesenheit auf das Handeln von Akteuren zurückzuführen ist, die feindselig, kriminell, unverantwortlich oder zumindest fahrlässig agieren.
Ökonomisierung
Ökonomisierung wird in gegenwärtigen Diskursen in der Regel zur Bezeichnung von Prozessen verwendet, in denen die spezifisch wirtschaftlichen Funktions-Elemente wie Markt, Wettbewerb/Konkurrenz, Kosten-Nutzen-Kalküle, Effizienz, Gewinnorientierung in Bereiche übertragen werden, die zuvor teilweise oder ganz nach anderen Leitkriterien ausgerichtet waren
Moralisierung
Moralisierung verlagert Macht- und Interessenkonflikte in die Sphäre der Kommunikation von Achtung / Missachtung. Sie reduziert Ambivalenz zugunsten einer Polarisierung von gut und böse.
Konstellationen
Krise
Krise ist vom Wort mit fachsprachlicher Bedeutung zur Zeitdiagnose und einem zentralen Begriff der öffentlich-politischen Kommunikation geworden. Der öffentlich-politische Krisenbegriff ist dabei – unabhängig vom Gegenstand der Krise – in eine krisendiskurstypische Konstellation zur Begründung von krisenüberwindenden Handlungen eingebettet.
Partizipatorischer Diskurs
Partizipation ist mittlerweile von der Forderung benachteiligter Personen und Gruppen nach mehr Beteiligung in der demokratischen Gesellschaft zu einem Begriff der Institutionen selbst geworden: Kein Programm, keine Bewilligung mehr, ohne dass bestimmte Gruppen oder Personen dazu aufgefordert werden, für (mehr) Partizipation zu sorgen.
Skandal
Die Diskurskonstellation des Skandals zeichnet sich durch eine in den Medien aufgegriffene (bzw. durch sie erst hervorgerufene) empörte Reaktion eines erheblichen Teils der Bevölkerung auf einen tatsächlichen oder vermeintlichen Missstand aus. Die schuldhafte Verursachung dieses Missstandes wird dabei einem gesellschaftlichen Akteur zugeschrieben, dessen Handeln als ‚unmoralisch‘ gedeutet wird.